Skip to content
0208 6000 500
Software
For Curtains & Blinds Online Retailers
For Auto Car parts – online retailers
Science Lab Management Software
Orderwise Development Agency
GenetiQ (formerly Intact Software)
Digital Asset Management Software
E-commerce
Web Design
Paid Marketing
Google Ads – PPC
Facebook Ads Management
Amazon Ads Management
Pinterest Paid Promotion
TikTok Paid Promotion
SEO
About
Faqs
Contact
Web Development
E-commerce Website Development
Magento Development Agency
WooCommerce Development Agency
Shopify Development Agency
Hyva Development Agency
Website Design and Web Development
WordPress Development
Starter websites <£2,500
Wix websites <£1,300
Branding & Graphic Design
Bespoke .Net Software & Solutions Developmnent
Progressive Web Apps (PWA)
Science Lab Management Software
Curtain Ordering Software
3rd Party Software Integration
Orderwise Software Integration
Corporate Web Hosting Services
Online Marketing
SEO Agency
Content Marketing
Core Web Vitals
Local Search Engine Optimisation
Conversion Rate Optimisation
Link Building Agency
Paid Marketing
Amazon PPC Management
TikTok Paid Promotion
Pinterest Paid Promotion
Google Adwords PPC
Bing Ads PPC
Facebook Ads Agency
Display Remarketing
Google Shopping
Email Marketing
Datadial Blog Archive
Articles & Insight
Category: Organic Search Marketing
Back to article list
Enquire now
My Biggest Link Building Success Story of 2014
Google Sabotage: There is No Such Thing as Negative SEO
Your Secret Weapon for Powerful Content Outreach: Native Advertising
Google, Penguins, and Unintended Consequences
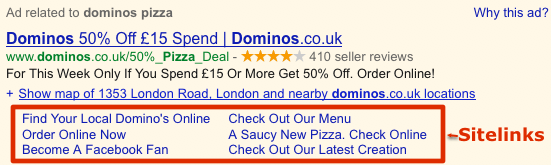
All You Need to Know About Google Sitelinks and Mini Sitelinks
How should you respond to Google’s announcement that Site Security is part of the ranking algorithm?
Parallax Design and SEO – Compatibility Problems
Google Goes After Brand Names With Its Comparison Engine.
Make Your 2014 SEO strategy SMARTER
Our Infographic was featured in The Times
Reducing Your Content Marketing to 1 Hour a Week
Link Reclamation – 7 Basic Wins
Previous
Next