

Whenever someone visits a site, they don’t really think about the nitty gritty details of its markup. And why should they? As a user-visitor, all they care about is getting to the good stuff, the content that’s actually important and will serve them well.
When Google’s crawler (the aptly named Googlebot) visits a page, it cares about a lot of the same things.
However, it does think about how the site is structured and even takes care to check out the stuff the web admin think is more important while neglecting pages that they’ve deemed unimportant.
“Wait, what? How does that happen?”, you may have asked. Allow me to explain.
Enter robots.txt: an amazing, if misunderstood, SEO tool
The robots.txt file is exactly what it sounds like: a text file named robots that resides in a website’s directory. In it, webmasters can place specific directives that tell crawlers like the Googlebot how they should be approaching the site.
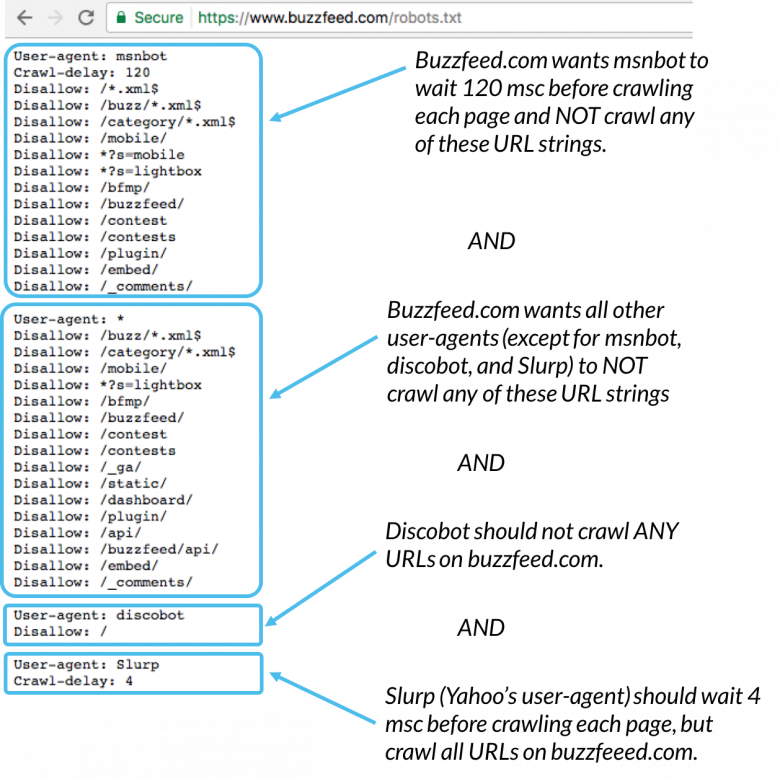
Google’s own guide to creating a robots.txt file will give you a glimpse on the beginnings of a standard robots file. Let’s take a look at the below:
User-agent: *
Allow: /
User-agent: Googlebot
Disallow: /lookaway
Sitemap: www.mysite.com/sitemap.xml
For many small sites, this is pretty much what their robots.txt will look like, albeit with their actual URLs. You begin by specifying a user-agent, such as Googlebot (* means everything except AdsBot).
Then, you simply tell it what pages are allowed to be crawled, and what should not be crawled. In the example above, we are saying that it’s cool for every crawler to visit every page of the site, but Googlebot should not visit the /lookaway page.
I would strongly recommend reading up on that directive to understand exactly how you should create the file, where it should be placed, and how directives should be spelled (e.g. everything is case-sensitive!).
So do all crawlers respect robots.txt?
No, not at all. Most benevolent crawlers, like Google’s own, will mostly respect the directives set in the robots.txt file. That is because they believe webmasters know their sites best, and will allocate their resources accordingly.
However, no malicious crawler will respect robots.txt. And there might be occasions where, for one reason or another, bots will simply forgo the directives and do what they want!
Importantly, some rules are changing
Recently, Google announced that the Robots Exclusion Protocol (REP), which is just a fancy way of referring to robots.txt files), will finally become an internet standard, along with going open source.
What this means for webmasters is that Google is cleaning up everything about robots.txt and issuing clear-cut, official rules for everything that goes inside said files.
Previously, a lot of unofficial directives were actively supported by Google, though the search giant has always been adamant about the fact that webmasters should never rely on them entirely.
Now, things like noindex, which have been used by SEO experts and webmasters for more than a decade, will no longer be supported by Google.
To put this in context, noindex was a directive that essentially told Googlebot that certain pages should not appear in search results. This was often used with the disallow and nofollow rules to essentially hide pages off the face of the Earth.
However, Google will still support and honor other directives that can have the same effect if used effectively, such as the disallow rule and noindex in meta tags instead of the robots.txt file.
You should still care about robots.txt for supported rules
While Google is changing some things, it’s not making robots.txt obsolete; far from it, in fact. All it wants to do is make sure that webmasters are not hurting their own sites by creating complicated and often contradicting rules for no reason.
Right now, the biggest focus for robots.txt files should be placed on managing crawl budgets. In essence, a crawl budget is the amount of resources Googlebot (and potentially other crawlers) will use on any specific site.
For example, if you have 5,000 pages, Googlebot will take its sweet time crawling all of them and may not even bother with some. If you use robots.txt to disallow URLs that are practically useless for search engines, however, then that budget can be used more effectively.
A case where this may have a huge influence, for instance, is a site that has a lot of query strings. Disallowing those means that you can instantly free up the crawl budget for hundreds of potential URLs, letting your more important pages be indexed and refreshed faster.
Some best practices
Using a robots.txt file effectively can be a great tool but a lot of people either go overboard or fail to understand its exact purpose. Here are some things you should and shouldn’t do:
- Don’t use robots.txt to block sensitive information. Instead, use password-protected portals or another secure method.
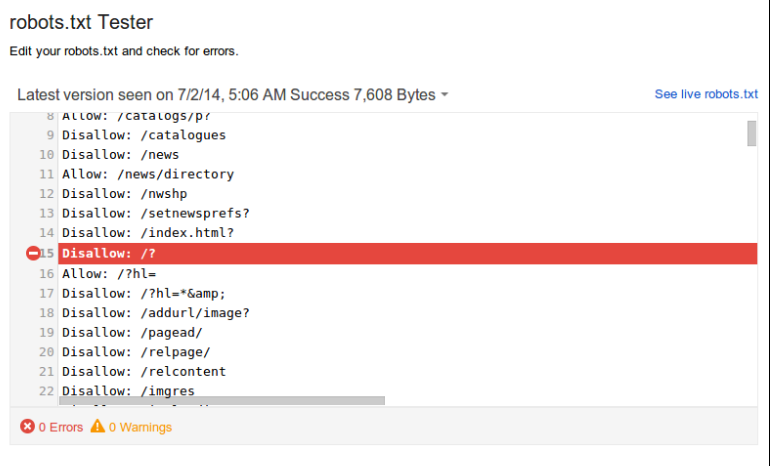
- Make sure you check your robots.txt file with google’s own Tester tool. After all, a small mistake means you might accidentally disallow huge areas of your site!
- Understand that when a crawler encounters a disallow, it will stop all activity. Which means that if you have a page that is only linked by a page that a crawler cannot get to, that page will most likely be hidden too.
When used effectively, a robots.txt file can augment your other SEO efforts and ensure that crawlers like the Googlebot can navigate your site effectively as well as make sure that junk pages are not visible on search engine results or eroding your crawl budget.
The tiny file costs nothing, is incredibly easy to create without any technical knowledge, and will potentially save you hundreds of hours of going through Google Search Console and manually removing indexed pages that should have never made it through!


